
Making Old Code Beautiful: Strings, Algorithm and Lambdas
Introduction
At university I was given an assignment to create a program that encoded some text using a mixed alphabet (described here) and printed the result. This works by putting a cypher word at the beginning of the alphabet then replacing the letters in the text by the equivalent in the cypher alphabet.
e.g. Using the cypher word “help” the word “world” becomes:

wnrjp
I wrote what I thought was good code but after returning to it years later I felt that I could rewrite the program making it much more elegant, using modern C++; something I originally couldn’t use since I didn’t have a C++11 compatible IDE and I wasn’t allowed to use str functions or strings due to the assignment specification.
This article is going to break down the replacement code and explain why I think what I’ve written now is better than what I wrote back at university. I will also benchmark the program to see if there was a performance impact from the rewrite.
I recommend downloading the source code now and jumping straight it but if you want a more detailed breakdown of the main changes I’ve made then you should continue reading.
Breaking it up
The original program was broken up into functions that solved small, contained problems, and when updating the code I tackled each of these problems separately. I will go through each problem and explain why I believe that the newer code is more readable without sacrificing performance.
Character storage
The first thing that changed was that I replaced all character arrays with strings. This simplifies function interfaces, since it’s no longer necessary to think about preserving null terminators or passing around the length of each string.
void TakeAString( const char* str, int size ); // This
void TakeAString( const char* str ); // or this
void TakeAString( const std::string& str ); // becomes this.
And since strings support move semantics, any function that outputs a string can return by value rather than altering it’s input. The ability to move a string makes this a good design choice that doesn’t sacrifice performance.
std::string ReturnString(); // Simple. We get a string.
void ReturnString( char* str ); // Ambiguous. What do we pass in?
Going from char arrays to strings does involve overhead, however, as string data is stored on the heap rather than the stack. It’s important to be careful when concatenating strings as this can create excess memory management if not done carefully.
Convert upper characters to lower characters
To convert upper case characters to lower case ones requires iterating over the string/char array. Previously I did this by reading characters until a null terminator was found but using strings, this detail can be ignored as I can use range based for loops to iterate.
Range based for loops are a convenient way of iterating over a whole container but by using STL algorithms I have exactly the same functionality but in a single line of code.
This:
char *read = string;
while( *read != NULL ) {
if( *read >= 'A' && *read <= 'Z' ) { // if letter is an upper case letter
// shift letter into lower case
*read = *read - 'A' + 'a';
}
read++;
}
Becomes:
// Convert to lower
std::transform(temp.begin(), temp.end(), temp.begin(), ::tolower );
The STL algorithm header is a collection of prewritten and tested algorithms (More information available here). Here, the function tolower is passed to std::transform to convert every character in the string to lower case.
By making use of algorithm the newer code is more readable and maintainable since there is just 1 line to consider. It’s also very well tested and almost definitely contains less bugs than the version I wrote originally.
Removing spaces and non character letters
Removing characters from a string is more complicated than just altering the characters. In the original implementation I used a read and a write pointer to iterate over a container and bump required elements closer to the start of an array, finally bringing forward the null terminator. From the point of view of performance this is actually very good but it’s not maintainable. Because the null terminator must be preserved, the code must constantly check whether the string has ended. It’s fiddly code and it’s difficult to read and understand, therefore the performance/elegance tradeoff isn’t worth it.
char *read = string;
char *write = string;
while( *write != NULL ) {
if( (*read >= 'a' && *read <= 'z') ||
(*read >= 'A' && *read <= 'Z') ||
*read == ' ' ||
*read == NULL ) {
// Move character forward
*write = *read;
read++;
write++;
}
else {
read++;
}
}
To avoid this I used another stl algorithm along with another new feature of C++11; the lambda. lambdas are small function objects that can be written inside calls to algorithm functions (for a good tutorial see here).
Since I wanted to remove characters from the string, based on a predicate so I used std::remove_if.
std::remove_if( temp.begin(), temp.end(), [] (char c) { return !isalpha(c); } );
The body of this lambda returns true on any character that isn’t a letter (which includes spaces), but there is still a problem with this code; consider the following string:
string str = "hell*o"; // Prints "helloo"
The output is wrong because the algorithm isn’t shrinking the string. Luckily, remove_if returns an iterator to the new end of the string. Combining the remove_if algorithm with the string member function erase means that we get a shorter string containing no spaces or non letters.
// Remove non letters
temp.erase( std::remove_if( temp.begin(), temp.end(), [] (char c) { return !isalpha(c); } ) , temp.end() );
I hope it’s clear why I think this code is more elegant. The goal of the original code was difficult to read, since the most important part was buried inside the condition of an if statement, while the new code is a recognisable pattern that makes it’s point very clear through the algorithm name. Also remember that the algorithms of the stl have been thoroughly tested and generally perform exactly the same as if we had written the implementations ourselves.
Remove repeated letters
To make the cypher-alphabet, the chosen word is combined with the alphabet, then letters are removed after their first occurrence.
The first way of doing this is to use more of algorithm. The result is this:
secondTemp.erase( std::copy_if(temp.begin(), temp.end(), secondTemp.begin(), [&secondTemp] (char c) { return secondTemp.find(c) == string::npos;} ), secondTemp.end() );
It’s a matter of personal opinion but I felt that this wasn’t the right solution. It’s difficult to read and it places responsibility on the calling code by requiring a temporary variable. The previous algorithm/lambda combination was simple, while this function within a lambda within a function, within a function, isn’t.
The other option, which I ultimately went with, was to write my own version of the algorithm and separate out the concerns into separate functions.
inline bool Contains( const string& str, const char value ) {
for( auto e : str ) {
if( e == value ) return true;
}
return false;
}
// Remove repeated letters. Order is preserved
string UniqueString( const string& input ) {
string temp;
temp.reserve( 26 );
for( auto e : input ) {
if( !Contains( temp, e ) ) {
temp += e;
}
}
return temp;
}
There are a few things to notice with this approach. The first is that the interface is very simple. UniqueString requires a constant reference to a string and it returns a string by value. This string will probably be moved into another variable at the calling site and so it probably shouldn’t incur a deep copy.
The second thing to notice is how simple the algorithm is, with the code being self documenting. Its a personal opinion but I prefer the two functions to the harder to read stl algorithm approach.
Results of hard work
I wanted to test whether these changes made the code better or worse. Since I changed the code to make it more elegant I wanted to test readability in some way and I didn’t want performance to be negatively effected so I needed to benchmark the program’s speed too.
Robustness and elegance
Unfortunately it’s difficult to test readability or elegance. Therefore, whether or not the code is more readable is subject to some personal opinion. My opinion is that the code is much better than it previously was because the number of lines of code have gone down, making the code easier to take in at once. I also believe that since the code now requires less comments to explain, since algorithm and function names explain their own purpose, it is more elegant and readable.
Because I used the algorithm header rather than write my own algorithms the code is now much safer and ideally less buggy. For example, it is now much harder to overflow the input buffers since strings can accept characters as long as there is enough system memory, while the original char arrays had a hard coded limit.
Performance
Since the original program didn’t use any dynamic memory management, anything that used strings (which use dynamic allocation) would be slower. To test the speed of both the old application and the updated version I used Google’s benchmark library.
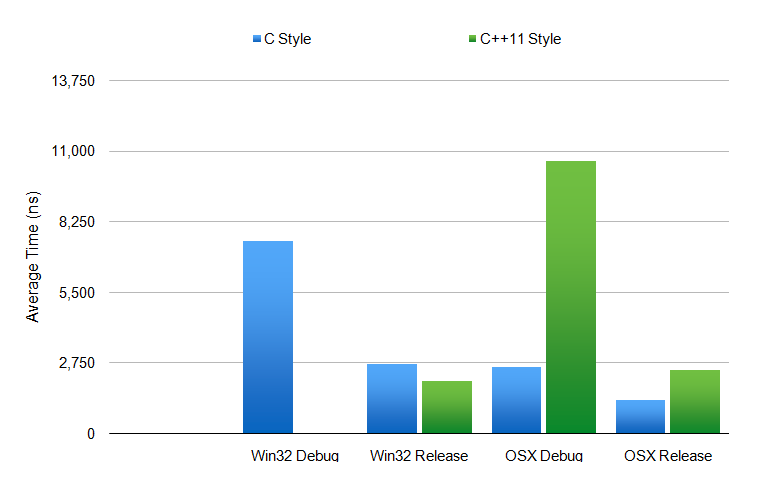
The graph shows that the compiler is better able to optimise the more modern C++ code making it comparable to the older code while still being more readable and maintainable.
Final thoughts
I was limited in the original assignment specification to not use features from the standard library. The point was to teach people how to iterate over a string using pointers, and while this is important to know, I believe that teaching people to rewrite standard library code makes them worse programmers (an opinion also expressed here).
Using modern C++ I was able to very quickly rewrite my old code. Rather than use char arrays and write every function myself it was easier to use strings with standard library algorithms, making use of the newer features of C++. Doing this made my code much easier to write, read and maintain while at the same time preserving the performance.
I am now of the opinion that unless there is a very good reason not to, such as failing a university assignment, you should always try to recognize opportunities to use code from the C++ standard library rather than writing your own solutions to problems that have already been solved.